ちょっとしたスクリプトをWindows/Linux/macOS兼用で動作させる
ちょっとそういうのが必要になったので
確か Embulk でこんな感じのことをやっていたはず…という記憶を頼りに作ってみた。 とりあえず動くけど、後述のとおり行儀のいい方法ではない&制約事項もあるので、使う場合は要注意。
環境
条件
- スクリプト内ではNode.jsで複数行のソースコードを実行したい。Node.jsはインストール済みでパスが通っている前提。
- 実行は1ファイルで完結させたい。実行時引数とかも無し。
- Windows(バッチファイル)でもLinux/macOS(bash/zsh)でも全く同じファイルを使う。
できあがったもの
こんな感じ。
: <<BAT @echo off echo ^ console.log('Node.js on Windows'); ^ let a = 1; ^ let b = 2; ^ console.log("a + b = " + (a + b)); | node.exe exit /b BAT node <<-EOS console.log('Node.js on Linux/macOS') let a = 1 let b = 2 console.log("a + b = " + (a + b)) EOS
runanywhere.bat 的な名前で保存し、各環境で実行する。
改行コードは LF にする。
実行例
Windows(コマンドプロンプト)
C:\work> runanywhere.bat Node.js on Windows a + b = 3
Linux(bash), macOS(zsh)
$ ./runanywhere.bat Node.js on Linux/macOS a + b = 3
仕組み
スクリプトの大枠は下記のとおり。
: <<BAT バッチファイル(Windows)として動作するコード exit /b BAT シェルスクリプト(Linux/macOS)として動作するコード
<<BAT ~ BAT にバッチファイルのコードを書いてあり、その後ろにシェルスクリプトのコードが続くという構成になっている。
シェルスクリプト(Linux/macOS)から見ると <<BAT ~ BAT の部分はコードはヒアドキュメントとして扱われ、: という何もしないコマンドに渡される。つまり、ただの文字列を何もしないコマンドに渡しているだけなので何も起こらず、その次に続くシェルスクリプトのコードが普通に実行される。
バッチファイル(Windows)から見ると : は GOTO コマンドのラベルであり、それだけでは特に何も処理は行われない。また、 : <<BAT のような表記も構文上は問題が無い。
このため、その次に続くバッチファイルのコードが普通に実行されて、最後に exit /b で終了する。それ以降のコードは実行されないので、後ろにシェルスクリプトのコードがあっても問題は無い。
あとは各環境でNode.jsにソースコードを渡して実行する処理を書けばOK。
シェルスクリプトの場合は普通にヒアドキュメントが書けるので、それをそのままNode.jsに流し込む。
バッチファイルの場合はヒアドキュメントが無いので、1行にまとめて標準入力経由でNode.jsにコードを渡している。
今回は読みやすさを考慮して ^ で改行しているが、実態は下記のようなコードと同じ。
echo console.log('Node.js on Windows'); let a = 1; let b = 2; console.log("a + b = " + (a + b)); | node.exe
制約事項
改行コードは LF にする必要がある。でないとLinux/macOSでエラーになる。バッチファイル的には良くないが、だいたい動くので許容する。
# CR/LFにすると… $ ./runanywhere.bat : not foundre.bat: 12: Node.js on Linux/macOS a + b = 3
ただし、日本語(マルチバイト文字)は使えない。バッチファイルで改行コードが LF の場合、日本語が含まれるとコマンドの一部が削られてしまい、エラーになる。
ちなみにこの挙動は マルチバイト文字を含まない場合にも発生することがあるらしい ので注意。
# こんな感じでコメントに日本語を入れてみると… : <<BAT @echo off rem 日本語 echo ^ ...
# 実行時にコマンドが削られてエラーになる C:\work>runanywhere.bat C:\work>ho off 'ho' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。 C:\work>m 日本語 'm' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。 ...
バッチファイルの部分を CR/LF 、シェルスクリプトの部分を LF にすれば解決するはずだけど、手作業で作るスクリプトでそれを維持し続けるのはさすがに厳しいので、LF に統一というのが落としどころだと思う。
まとめ
とりあえず動くので使えるんだけど、改行コードが LF のバッチファイルってことであまり良くないので、多用は禁物。
xargsで複数のパラメータに対してプレースホルダを使う
環境
- Ubuntu 22.04
xargsで -n と -I が併用できない問題
xargs を使う際、-I オプションを使ってパラメータをプレースホルダに差し込むというのをよくやります。
# テスト用ファイル $ cat data.txt aaaa bbbb cccc dddd # ファイルの各行に対して xargs でコマンド実行 # -I で指定したプレースホルダ @ の場所にパラメータが正しく置換されている $ cat data.txt | xargs -I@ echo "The input is [@]." The input is [aaaa]. The input is [bbbb]. The input is [cccc]. The input is [dddd].
パラメータが1つの場合はこれでいいんですが、-n オプションで2つ以上のパラメータを使おうとすると -I が使えないため、すごく困ります。
# xargs -n2 でパラメータ2つずつに対してコマンド実行 # 先に指定した -I@ が無視されて -n2 だけが有効になり、パラメータの置換が行われない $ cat data.txt | xargs -I@ -n2 echo "The inputs are [@]." xargs: warning: options --replace and --max-args/-n are mutually exclusive, ignoring previous --replace value The inputs are [@]. aaaa bbbb The inputs are [@]. cccc dddd
sh -c 経由で実行して回避する
これは xargs に渡すコマンドを sh -c 経由で実行し、シェルの引数 $1, $2, ... を使うことで代替できます。
$ cat data.txt | xargs -n2 sh -c 'echo "The inputs are [$1, $2]."' sh The inputs are [aaaa, bbbb]. The inputs are [cccc, dddd].
xargs から sh -c 'echo "The inputs are [$1, $2]."' sh aaaa bbbb のような形で sh にパラメータが渡されるので、あとは sh で実行するコマンドの中で $1, $2 等を好きなように使えばOK、という具合です。
コマンド末尾の sh は、 $0 として渡されるコマンド名を明示的に指定しているだけです。
今回の場合であればこれを無くして xargs -n2 sh -c 'echo "The inputs are [$0, $1]."' のようにしてもよいのですが、例えばコマンド内で $@ を使った場合に $0 は除外されるといった扱いの違いもあるので、指定しておくとちょっとだけ安心です。
参考
SQLで is null or 〜 を一発でやる is distinct from の話
環境
- PostgreSQL 15
- 本記事の機能はPostgreSQLで試していますが、
is distinct fromはANSI標準なので、他のDBMSでもサポートされていれば使えます
- 本記事の機能はPostgreSQLで試していますが、
SQLで null を含むカラムへの条件指定
ご存知のとおり、SQLでの値の比較の際に = とか <> とかで null と比較すると、結果は常に null になります。
このため、null を含むカラムに対して「ある値に一致しない行を、null も含めて出したい」みたいなことをやる場合は is null の条件も加えて比較する必要があります。
例: テーブル nantoka_data
-- 元データ select * from nantoka_data;
| id | name | num |
|---|---|---|
| 1 | 'foo' | 100 |
| 2 | 'bar' | 200 |
| 3 | null | null |
-- num が null の行は num <> 100 だと抽出されない select * from nantoka_data where num <> 100;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
-- is null の条件を加えて、カラム num の値が 100 と一致しない行を全て抽出する select * from nantoka_data where num is null or num <> 100;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
| 3 | null | null |
is distinct from を使ってみる
で、これを一発で行う is distinct from というものがあります。
入力のどちらかがnullの場合、通常の比較演算子は真や偽ではなく(「不明」を意味する)nullを生成します。 例えば7 = nullはnullになります。7 <> nullも同様です。 この動作が適切でない場合は、IS [ NOT ] DISTINCT FROM述語を使用してください。
a IS DISTINCT FROM b a IS NOT DISTINCT FROM b
これを使って前述のSQLを書き換えると、こんな感じ。
-- select * from nantoka_data where num is null or num <> 100; と同じ select * from nantoka_data where num is distinct from 100;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
| 3 | null | null |
ちなみに構文は expression IS DISTINCT FROM expression なので、値だけでなく式が書けます。
このため、値の一致のみでなく、大小比較や like での部分一致なんかもできます。
-- num < 150 に該当しない行を、nullも含めて抽出 select * from nantoka_data where num < 150 is distinct from true;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
| 3 | null | null |
-- name like 'b%' に該当しない行を、nullも含めて抽出 select * from nantoka_data where name like 'b%' is distinct from true;
| id | name | num |
|---|---|---|
| 1 | 'foo' | 100 |
| 3 | null | null |
正直ちょっと冗長なので is null or 〜 と書いてもあまり変わらない気がするのと、「どこにも not って書いてないのに否定条件」というところに若干のわかりづらさはありますが、覚えておくとどこかで使えるかもしれません。
参考
複合インデックスを使うにはwhere句に書くカラムの順番を合わせないとダメとか無いですよねという話
概要
「複合インデックスを使うにはwhere句に書くカラムの順番をインデックスの定義順と合わせなければならんのじゃよ *1」って言われて、いやそんなまさか…?と思ったので念のため検証してみたメモ。
結論から言うと、試した限りではそんなことはなかった。
どういうことかというと
こういうテーブルとインデックスがあったときに…
create table sample_data ( id integer primary key, colum_a integer not null, colum_b integer not null, colum_c integer not null ); create index idx_sample_data_01 on sample_data (colum_a, colum_b, colum_c);
こう書くと複合インデックス idx_sample_data_01 が使われるけど
-- where句のカラムの順番を複合インデックスでの定義順 colum_a, colum_b, colum_c に合わせる select * from sample_data where colum_a = 100 and colum_b = 100 and colum_c = 100;
こう書くと使われない、という主張らしい。
-- where句のカラムの順番を複合インデックスでの定義順とは異なる順番にする select * from sample_data where colum_c = 100 and colum_b = 100 and colum_a = 100;
というわけで試してみる
環境
- PostgreSQL 15.3
- MySQL 8.0.33
いずれもDocker Hubの公式イメージを使う。
手順
1. Dockerコンテナ立ち上げ
$ docker run -d \ --name postgres \ -p 127.0.0.1:5432:5432 \ -e POSTGRES_PASSWORD=postgres \ -v pgdata:/var/lib/postgresql/data \ postgres:15.3 $ docker run -d \ --name mysql \ -p 127.0.0.1:3306:3306 \ -e MYSQL_ROOT_PASSWORD=mysql \ mysql:8.0.33
2. テーブルを作ってデータを投入
前述のテーブルにデータを50,000件入れて試してみる。
こんな感じのSQLファイルを作っておいて
-- insert.sql create table sample_data ( id integer primary key, colum_a integer not null, colum_b integer not null, colum_c integer not null ); create index idx_sample_data_01 on sample_data (colum_a, colum_b, colum_c); insert into sample_data values (1, 1, 1, 1), (2, 2, 2, 2), (3, 3, 3, 3), -- 中略 (49999, 49999, 49999, 49999), (50000, 50000, 50000, 50000);
各DBに投入する。analyze もやっておく。
# PostgreSQL $ psql -h localhost -U postgres -f insert.sql $ psql -h localhost -U postgres -c 'analyze sample_data;' # MySQL $ mysql -p -u root mysql < insert.sql $ mysql -p -u root mysql -e 'analyze table sample_data;'
ちなみにデータはこんな感じのRubyコードで作ったもの。
values = 1.upto(50000).map {|n| "(%d, %d, %d, %d)" % [n, n, n, n] }.join(",\n") puts "insert into sample_data values #{values};"
4. 試してみる
各条件で実行計画を取得してみて、インデックスが使われるかどうかを確認する。
PostgreSQL
まずはwhere句のカラムの順番を複合インデックスでの定義順に合わせた状態でやってみる。 これは当然インデックスが使われる。
explain verbose select * from sample_data where colum_a = 100 and colum_b = 100 and colum_c = 100;
QUERY PLAN | -----------------------------------------------------------------------------------------------------------+ Index Scan using idx_sample_data_01 on public.sample_data (cost=0.29..8.31 rows=1 width=16) | Output: id, colum_a, colum_b, colum_c | Index Cond: ((sample_data.colum_a = 100) AND (sample_data.colum_b = 100) AND (sample_data.colum_c = 100))|
QUERY PLAN が Index Scan using idx_sample_data_01 〜 となっているので、ちゃんと複合インデックスが使われていることがわかる。
次にwhere句のカラムの順番を複合インデックスでの定義順とは逆にしてみる。
explain verbose select * from sample_data where colum_c = 100 and colum_b = 100 and colum_a = 100;
QUERY PLAN | -----------------------------------------------------------------------------------------------------------+ Index Scan using idx_sample_data_01 on public.sample_data (cost=0.29..8.31 rows=1 width=16) | Output: id, colum_a, colum_b, colum_c | Index Cond: ((sample_data.colum_a = 100) AND (sample_data.colum_b = 100) AND (sample_data.colum_c = 100))|
…普通にインデックス使われている様子。コストも全く一緒。
さらに順番を入れ替えてみたけど、やっぱり結果は同じ。
explain verbose select * from sample_data where colum_c = 100 and colum_a = 100 and colum_b = 100;
QUERY PLAN | -----------------------------------------------------------------------------------------------------------+ Index Scan using idx_sample_data_01 on public.sample_data (cost=0.29..8.31 rows=1 width=16) | Output: id, colum_a, colum_b, colum_c | Index Cond: ((sample_data.colum_a = 100) AND (sample_data.colum_b = 100) AND (sample_data.colum_c = 100))|
MySQL
where句のカラムの順番を複合インデックスでの定義順に合わせた場合。 当然インデックスが使われる。
explain select * from sample_data where colum_a = 100 and colum_b = 100 and colum_c = 100;
Name |Value | -------------+------------------+ id |1 | select_type |SIMPLE | table |sample_data | partitions | | type |ref | possible_keys|idx_sample_data_01| key |idx_sample_data_01| key_len |12 | ref |const,const,const | rows |1 | filtered |100.0 | Extra |Using index |
type = ref、key = idx_sample_data_01 なので、ちゃんと複合インデックスが使われている。
PostgreSQLと同様、順番を逆にしたり入れ替えたりしてもやっぱり結果は変わらず。
explain select * from sample_data where colum_c = 100 and colum_b = 100 and colum_a = 100;
Name |Value | -------------+------------------+ id |1 | select_type |SIMPLE | table |sample_data | partitions | | type |ref | possible_keys|idx_sample_data_01| key |idx_sample_data_01| key_len |12 | ref |const,const,const | rows |1 | filtered |100.0 | Extra |Using index |
explain select * from sample_data where colum_c = 100 and colum_a = 100 and colum_b = 100;
Name |Value | -------------+------------------+ id |1 | select_type |SIMPLE | table |sample_data | partitions | | type |ref | possible_keys|idx_sample_data_01| key |idx_sample_data_01| key_len |12 | ref |const,const,const | rows |1 | filtered |100.0 | Extra |Using index |
こんな話はどこから出てきた?
試した結果を見てそりゃそうだよなと思いつつもうちょっと調べてみると、「達人に学ぶSQL徹底指南書」の初版第4刷 p.205 にはこんなことが書いてあった。
(col_1, col_2, col_3) に対してこの順番で複合インデックスが張られているとします。 その場合、条件指定の順番が重要です。
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500; ○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100; × SELECT * FROM SomeTable WHERE col_1 = 10 AND col_3 = 500; × SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500; × SELECT * FROM SomeTable WHERE col_2 = 100 AND col_1 = 10;
必ず最初の列(col_1)を先頭に書かねばなりませんし、順番も崩してはいけません。
最後の例は条件を col_2, col_1 の順番で書いていて × となっているので、今回の話と合致する。
しかし同書籍の第2版では下記のように変わっており、WHERE col_2 = 100 AND col_1 = 10 の例が無くなっている。
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500; ○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100; × SELECT * FROM SomeTable WHERE col_1 = 10 AND col_3 = 500; × SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500;
初版の正誤表 にも当該部分の記載が無いので、もしかしたら昔はそういう制約事項があったのかもしれない。
まとめ
少なくとも PostgreSQL 15.3 と MySQL 8.0.33 では、where句のカラムの順番を複合インデックスの定義順と合わせなくても大丈夫そう。
いにしえのDBは知らん。
参考
各DBの実行計画の読み方の参考。
IntelliJ IDEAでSpring Bootの@Valueアノテーションの引数にプロパティ値が展開されないようにする
環境
概要
いつの頃からか、IntelliJ IDEAでSpring Bootの @Value アノテーションの引数部分に実際のプロパティ値が展開されるようになりました。
こう書くと…
# application.yaml demo: someString: nanraka no mojiretsu
public class DemoController { @Value("${demo.someString}") String someString; }
↓こうなる
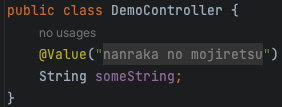
すごくウザいので、OFFにします。
こうする
メニューから
IntelliJ IDEA > Preferences... > Editor > General > Code Foldingと設定画面を開き *1 、Java の I18n strings のチェックを外します。

あとはOKボタンでダイアログを閉じてIntelliJ IDEAを終了し、再度起動すればOK。
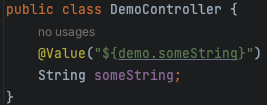
ソースコードに書かれたとおりのキーが表示されるようになりました。
参考
BSD版xargsの -I オプションで長い文字列を置換する場合は -S で replsize の設定が必要
久しぶりなので小ネタ。
環境
- macOS Big Sur 11.7
なにごと?
いつものように xargs -I でコマンドを置換して諸々やっていたのですが、あるときなぜかうまく置換されないことがあったのです。
これは期待どおり。
$ echo 'short' | xargs -I@ echo '[@]' [short]
しかし xargs に渡す値が長くなると置換されず、 -I で指定した文字がそのまま出てきてしまう…。
$ echo 'looo(中略)ooong' | xargs -I@ echo '[@]' [@]
調べてみる
というわけで man を見てみると…
$ man xargs
XARGS(1) BSD General Commands Manual XARGS(1)
NAME
xargs -- construct argument list(s) and execute utility
SYNOPSIS
xargs [-0oprt] [-E eofstr] [-I replstr [-R replacements] [-S replsize]]
[-J replstr] [-L number] [-n number [-x]] [-P maxprocs] [-s size]
[utility [argument ...]]
(中略)
-I replstr
Execute utility for each input line, replacing one or more occurrences of replstr in up to replacements (or 5 if no -R flag is specified) arguments to utility with the entire line of input. The
resulting arguments, after replacement is done, will not be allowed to grow beyond replsize (or 255 if no -S flag is specified) bytes; this is implemented by concatenating as much of the argument
containing replstr as possible, to the constructed arguments to utility, up to replsize bytes. The size limit does not apply to arguments to utility which do not contain replstr, and furthermore,
no replacement will be done on utility itself. Implies -x.
-S replsize
Specify the amount of space (in bytes) that -I can use for replacements. The default for replsize is 255.
つまり -I で置換する値は replsize のサイズ(単位はバイト)を超えてはダメでデフォルトは 255 バイト、変更するには -S オプションを使えばOK。
解決
というわけで、今回のやつはこんな感じでサイズ指定すればよいのでした。
$ echo 'looo(中略)ooong' | xargs -S1024 -I@ echo '[@]' [loooooooooo ... oooooooooooong]
Helmのtemplateでループ内から変数を参照する
環境
- helm v3.8.0
背景
こんな感じで、ほぼ同じ内容のマニフェストを複数作りたいとする。
当然 values.yaml で変数を管理したいし、2つ分コピペするのではなくループでうまいこと処理したい。
# targetgroupbinding.yaml apiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: my-target-group-binding-1 spec: serviceRef: name: awesome-service port: 8080 targetGroupARN: "arn:aws:elasticloadbalancing:ap-northeast-3:999999999999:targetgroup/awesome-service-1/zzzzzzzzzzzzzzzz" --- apiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: my-target-group-binding-2 spec: serviceRef: name: awesome-service port: 8081 targetGroupARN: "arn:aws:elasticloadbalancing:ap-northeast-3:999999999999:targetgroup/awesome-service-2/zzzzzzzzzzzzzzzz"
values.yaml がこんな感じだとする。
# values.yaml appName: awesome-service service: foo: id: 1 port: 8080 targetGroupARN: "arn:aws:elasticloadbalancing:ap-northeast-3:999999999999:targetgroup/awesome-service-1/zzzzzzzzzzzzzzzz" bar: id: 2 port: 8081 targetGroupARN: "arn:aws:elasticloadbalancing:ap-northeast-3:999999999999:targetgroup/awesome-service-2/zzzzzzzzzzzzzzzz"
パターン1:ループ中にyaml本体を直接書く場合
サンプル全体: https://github.com/ser1zw/helm-loop-demo/tree/main/demo1
普通にループで処理するなら、TargetGroupBindingのyamlはこんな感じ。
# targetgroupbinding.yaml {{- range .Values.service }} apiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: my-target-group-binding-{{ .id }} spec: serviceRef: name: {{ $.Values.appName }} port: {{ .port }} targetGroupARN: {{ quote .targetGroupARN }} --- {{- end -}}
{{- range .Values.service }} ~ {{- end -}} の間ではコンテキストが .Values.service のそれぞれの値になるので(後述の「参考:ループ内のコンテキストの値」参照)、.Values.service.* 配下の値は .id, port, .targetGroupARN のように直接参照できる。
逆に values.yaml で定義した appName は .Values.appName では参照できない。この場合は、ルートコンテキストを指すグローバル変数 $ を使い、 $.Values.appName のように参照する。
参考:ループ内のコンテキストの値
{{- range .Values.service }} ~ {{- end -}} 内でのコンテキストはこんな感じのmapになっている
map[id:1 port:8080 targetGroupARN:arn:aws:elasticloadbalancing:ap-northeast-3:999999999999:targetgroup/awesome-service-1/zzzzzzzzzzzzzzzz] map[id:2 port:8081 targetGroupARN:arn:aws:elasticloadbalancing:ap-northeast-3:999999999999:targetgroup/awesome-service-2/zzzzzzzzzzzzzzzz]
ちなみにこんな感じで表示して確認できる。
{{- range .Values.service }} ctx: {{ . }} {{- end -}}
パターン2:テンプレートを使う場合
サンプル全体: https://github.com/ser1zw/helm-loop-demo/tree/main/demo2
さまざまな事情により、yaml本体をループ中に直接書くのではなく、名前付きテンプレートにしたいということもよくある。
こうする。
# targetgroupbinding.yaml {{- range .Values.service }} {{- $ctx := (merge (dict "rootCtx" $) .) -}} # <-- ポイント(1) {{ template "target-group-binding-template" $ctx }} {{- end -}}
# _helpers.tpl {{- define "target-group-binding-template" }} apiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: my-target-group-binding-{{ .id }} spec: serviceRef: name: {{ .rootCtx.Values.appName }} # <-- ポイント(2) port: {{ .port }} targetGroupARN: {{ quote .targetGroupARN }} --- {{- end }}
テンプレートは {{ template テンプレート名 コンテキスト }} で呼び出せるが、コンテキストは1つしか渡せない。
そこで ポイント(1) のように、ループ時点でのルートコンテキスト $ とループ内のコンテキスト . をマージした上で渡してやる。
ここではルートコンテキストのキーを rootCtx にしているが、これは何でもよい。
こうすることで、テンプレート内ではループ内のコンテキストの値は普通に .id のように参照できるし、元のルートコンテキストの値は ポイント(2) のように rootCtx を使って .rootCtx.Values.appName のように参照できる。
ちなみに今回は template を使っているが、include でも同じ。
ダメな例
公式ドキュメントだと template の呼び出し時のコンテキストに . を渡す例しかないので、そのまま . を渡しがち。
# targetgroupbinding.yaml {{- range .Values.service }} {{ template "target-group-binding-template" . }} # <-- これ {{- end -}}
で、テンプレート内でルートコンテキストを参照するために $ を使おうとすると…
# _helpers.tpl {{- define "target-group-binding-template" }} apiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: my-target-group-binding-{{ .id }} spec: serviceRef: name: {{ $.Values.appName }} # <-- これ port: {{ .port }} targetGroupARN: {{ quote .targetGroupARN }} --- {{- end }}
こんな感じでエラーになる。
Error: template: demo/templates/_helpers.tpl:8:14: executing "target-group-binding-template" at <$.Values.appName>: nil pointer evaluating interface {}.appName
Use --debug flag to render out invalid YAML
なんでかというと、template にループ内のコンテキスト . を渡しているので、テンプレート内では ルートコンテキスト = ループ内のコンテキスト になってしまっているため。