ProxmoxでおうちKubernetes環境を作った
お正月なので
使っていないPCにProxmoxを入れて、おうちKubernetes環境を構築しました。
余ってたPCにProxmox入れておうちk8s環境ができたので喜びの舞 pic.twitter.com/Yh03sp2wek
— ser1zw (@ser1zw) January 2, 2025
構成
Proxmox上の仮想マシン(Ubuntu)でKubernetesを動かします。 Kubernetesのノードはコントロールプレーン1台、ワーカーノード2台という構成とします。
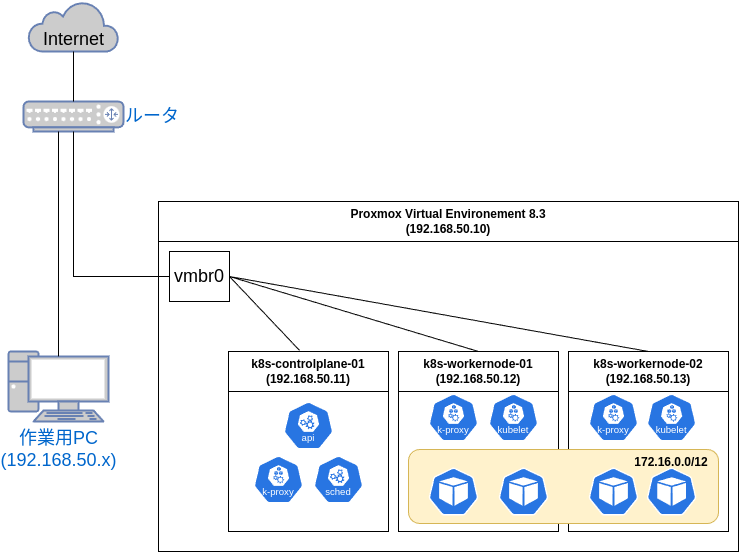
- Proxmox用PC
- 仮想化環境:
- Kubernetes環境
- Kubernetes本体: Kubernetes 1.32
- コンテナランタイム: cri-o 1.32
- CNIプラグイン: Calico 3.29.1
- ホストOS: Ubuntu Server 24.04.1 LTS
仮想マシンのスペック
スペックはコントロールプレーン、ワーカーノード共通で下記のとおり。
- CPU: 1ソケット2コア
- メモリ: 4GB
- ディスク: 32GB
各マシンのホスト名およびIPアドレス
- Proxmox
pve: 192.168.50.10
- Kubernetesコントロールプレーン
k8s-controlplane-01: 192.168.50.11
- Kubernetesワーカーノード
k8s-workernode-01: 192.168.50.12k8s-workernode-02: 192.168.50.13
- KubernetesのPod用セグメント: 172.16.0.0/12
構築
方針
- ProxmoxよくわかんないのでひとまずGUIでVMを作ります。本当は Terraform とか cloud-init とか Ansible とかでやりたいけどそれはまた今度。
- Kubernetesもよくわかんないのでおとなしく
kubeadmで作ります。 - セキュリティ面は見なかったことにします。各自いい感じにやってくれ。
構築手順
1. Proxmoxのセットアップ
まずはProxmoxのISOファイルを このへん からダウンロードしてきます。
ダウンロードできたら、そのへんのUSBメモリに書き込めばOK。dd コマンドでやるならだいたいこんな感じ。
$ sudo dd if=./proxmox-ve_8.3-1.iso of=/dev/sdc status=progress bs=1KB
USBメモリができあがったらPCに挿してUSBブートすればインストーラが起動するので、あとはインストーラにしたがって進めていけばOK。
インストールが終わったらPCを再起動するとProxmoxにログインできるようになるので、PCにディスプレイとキーボードを挿したり別の端末からブラウザでWeb UI https://192.168.50.10:8006/ にアクセスしたりしていじります。
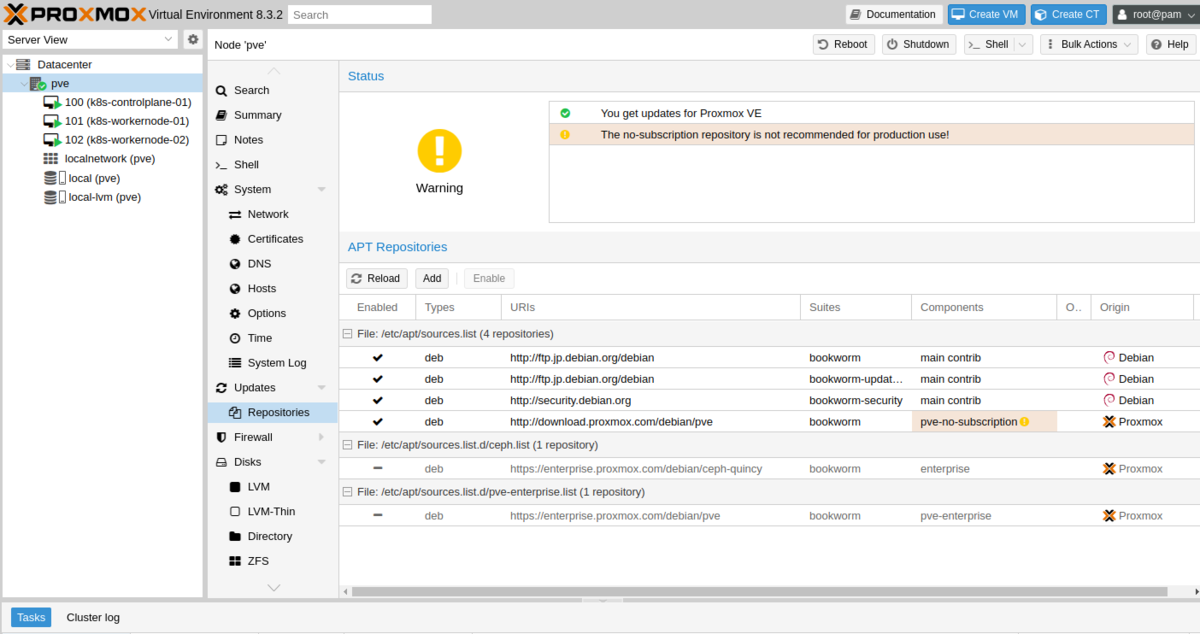
なお、このタイミングでProxmoxのサブスクリプション無し版リポジトリの追加&アップデートをしておくとよいです。
左メニューのDatacenter配下のノードを選択して Update > Repositories を開き、Add ボタンから Repository: No-Subscription を追加します。
ついでにEnterpriseっぽい https://enterprise.proxmox.com/debian/ceph-quincy と https://enterprise.proxmox.com/debian/pve を選択して Disable で無効化し、 Repositories の上の Updates メニューで Refresh、Upgrade していけばOKです。
2. Kubernetesノード用のVM構築
ProxmoxのWeb UI https://192.168.50.10:8006/ から作成していきます。
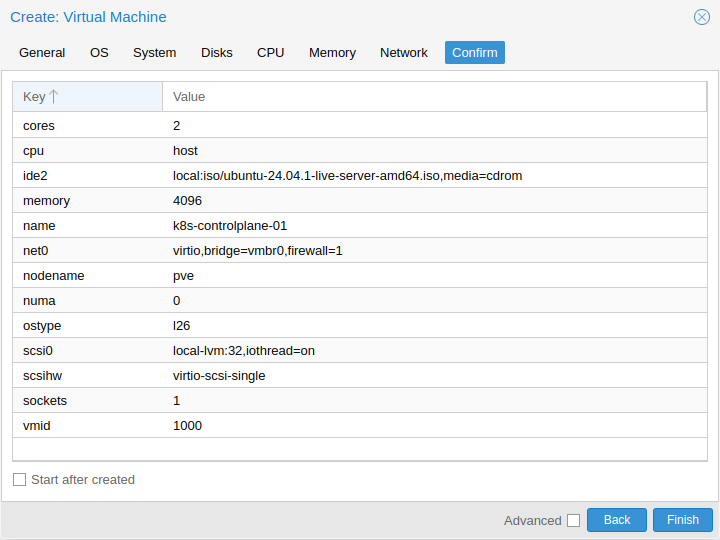
と言っても基本的には画面右上の Create VM ボタンからぽちぽちやっていくだけです。
変えたのは下記項目。その他はデフォルトのまま。
| タブ | 項目名 | 値 |
|---|---|---|
| General | Name | ホスト名(k8s-controlplane-01, k8s-workernode-01, k8s-workernode-02) |
| OS | Use CD/DVD disc image file (iso) > ISO image | UbuntuのISOイメージ(事前に左メニュー local > ISO Images からアップロードしておく) |
| CPU | Cores | 2 |
| CPU | Type | host |
| Memory | Memory (MiB) | 4096 |
あとはVMを起動し、 Console からインストールしていけばOK。
これをコントロールプレーン用1台、ワーカーノード用2台の計3台分行います。
3. Kubernetesコントロールプレーンの構築
ProxmoxのコンソールまたはsshでコントロールプレーンのVM k8s-controlplane-01 内から操作していきます。
3-1. インストール前の事前準備
何はなくともまずは諸々アップデート
$ sudo apt-get update && sudo apt-get upgrade -y && sudo apt-get autoremove -y && sudo apt-get autoclean -y
スワップをOFFにします。永続化のため、 /etc/fstab で # /swap.img 〜 の行を削除orコメントアウトしておきます。
$ sudo swapoff -a $ sudo vi /etc/fstab # /swap.img none swap sw 0 0 # 削除orコメントアウト
cat /proc/swaps でスワップの内容が表示されなくなることを確認。
$ cat /proc/swaps Filename Type Size Used Priority
カーネルモジュール br_netfilter の有効化と、カーネルパラメータ net.ipv4.ip_forward の設定を行います。
$ echo "br_netfilter" | sudo tee /etc/modules-load.d/k8s.conf $ echo "net.ipv4.ip_forward = 1" | sudo tee /etc/sysctl.d/k8s.conf $ sudo sysctl --system
3-2. cri-o, Kubernetesのインストール
だいたい cri-oのREADME の記載に従って進めていきます。
まずはバージョンを環境変数に入れておき…
$ KUBERNETES_VERSION=v1.32 $ CRIO_VERSION=v1.32
cri-o, Kubernetesのリポジトリを追加して apt-get でインストール。
$ curl -fsSL https://pkgs.k8s.io/core:/stable:/$KUBERNETES_VERSION/deb/Release.key |
sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
$ echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/$KUBERNETES_VERSION/deb/ /" |
sudo tee /etc/apt/sources.list.d/kubernetes.list
$ curl -fsSL https://pkgs.k8s.io/addons:/cri-o:/stable:/$CRIO_VERSION/deb/Release.key |
sudo gpg --dearmor -o /etc/apt/keyrings/cri-o-apt-keyring.gpg
$ echo "deb [signed-by=/etc/apt/keyrings/cri-o-apt-keyring.gpg] https://pkgs.k8s.io/addons:/cri-o:/stable:/$CRIO_VERSION/deb/ /" |
sudo tee /etc/apt/sources.list.d/cri-o.list
$ sudo apt-get update
$ sudo apt-get install -y cri-o kubelet kubeadm kubectl
インストールが完了したら、意図しないバージョンアップを避けるためバージョンを固定しておきます。
$ sudo apt-mark hold cri-o kubelet kubeadm kubectl
cri-o のサービスを立ち上げておき…
$ sudo systemctl start crio.service
念のためVMを再起動。
$ sudo shutdown -r now
3-3. コントロールプレーン構築
起動したら再度VMに入り、いよいよKubernetesのコントロールプレーンを構築していきます。
kubeadm コマンドにPod用ネットワークセグメント 172.16.0.0/12 を渡して実行。
$ sudo kubeadm init --pod-network-cidr=172.16.0.0/12
成功すると下記のようなメッセージが表示されます。最後の kubeadm join コマンドはワーカーノード作成時に使うので、忘れずに控えておきます。
Your Kubernetes control-plane has initialized successfully!
(中略)
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.50.11:6443 --token ******.**************** \
--discovery-token-ca-cert-hash sha256:****************************************************************
3-4. kubectl コマンド用の設定
$ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config
これで kubectl get pods とかできるようになります。
3-5. Calicoのインストール
今回はCNIプラグインとしてCalicoを使います。インストールの流れはほぼ Calicoのドキュメント のとおりでOK。
まずはCalicoのマニフェストをダウンロードします。
$ wget https://raw.githubusercontent.com/projectcalico/calico/v3.29.1/manifests/tigera-operator.yaml $ wget https://raw.githubusercontent.com/projectcalico/calico/v3.29.1/manifests/custom-resources.yaml
ここで1点注意。custom-resources.yaml にはPodのネットワークセグメントが 192.168.0.0/16 と直接書かれているので、今回のネットワークセグメントに合わせて書き換える必要があります。
$ vi custom-resources.yaml
# cidr: 192.168.0.0/16 # 削除orコメントアウト
cidr: 172.16.0.0/12 # 追加
編集が終わったら kubectl create でデプロイします。
$ kubectl create -f tigera-operator.yaml $ kubectl create -f custom-resources.yaml
しばらく待って、 kubectl get nodes で STATUS が Ready に、kubectl get pods -A で全Podの STATUS が Running になれば完了です。
4. Kubernetesワーカーノードの構築
ワーカーノードのVM k8s-workernode-01、k8s-workernode-02 で操作していきます。
まずは 3. kubernetesコントロールプレーンの構築 の最初から 3-2. cri-o, Kubernetesのインストール まで、コントロールプレーンと同じ手順で進めます。
完了後、3-3. コントロールプレーン構築 の最後で控えた kubeadm join コマンドを実行すればノードがクラスタに追加されます。
$ sudo kubeadm join 192.168.50.11:6443 --token ******.**************** \
--discovery-token-ca-cert-hash sha256:****************************************************************
コントロールプレーンのVMで kubectl get nodes を実行し、ワーカーノードが表示されていればOK。
$ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-controlplane-01 Ready control-plane 16h v1.32.0 k8s-workernode-01 Ready <none> 16h v1.32.0 k8s-workernode-02 Ready <none> 16h v1.32.0
試してみる
コントロールプレーン k8s-control-plane-01 でこんな感じのyamlを用意しておき…
# nginx.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx replicas: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.27.3 ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: type: NodePort ports: - port: 8080 targetPort: 80 nodePort: 30080 protocol: TCP selector: app: nginx
# toolbox.yaml # https://github.com/ser1zw/toolbox-container apiVersion: v1 kind: Pod metadata: name: toolbox spec: containers: - name: toolbox image: ser1zw/toolbox:latest
デプロイします。
$ kubectl apply -f nginx.yaml $ kubectl apply -f toolbox.yaml
nginxに別のPodからcurlでアクセスすると、正常に応答が返ってきます。いい感じ。
$ kubectl exec toolbox -- curl -s nginx:8080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> (中略) </html>
ついでに上記マニフェストではServiceをNodePortにしているので、ホストマシンと同一ネットワーク上の別端末からノードのIPを指定してcurlを実行しても(ファイヤウォールが開いていれば)応答が返ってきます。
$ curl -s 192.168.50.12:30080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> (中略) </html>
完璧ですね。
まとめ
というわけで、無事おうちKubernetes環境が構築できました。
今回は手動でGUI操作したりコマンド実行したりしましたが、何台もあるとめんどくさいのでIaC化しておきたいところです。
参考
ThinkPad X201iにUbuntu 24.04を入れたらフリーズしたのでなんとかした
なにごと?
ThinkPad X201iにUbuntu 24.04をインストールしようとしたらフリーズして操作不能になったのでなんとかしましたという話です。
環境
発生事象
いつものとおり、Ubuntu 24.04のISOをUSBメモリに書き込み、USBメモリから起動する。 なんか嫌な予感のするエラーを吐き出しつつも、インストーラが起動する。
が、インストールを進めていくと、画面が途中で動かなくなる。 キーボードやマウス(トラックポイント)の操作も受け付けない様子。 何回か試したけど発生するタイミングは決まっておらず、「しばらく操作していると固まる」という状態。
対応方法
起動オプションに nomodeset をつけて、Kernel mode settingを無効化する。
インストール時の対応
USBメモリから起動する際のGRUBメニューで Try or Install Ubuntu を選択状態にして e キーを押す。
下記のような表示になるので、vmlinuz の行の末尾に nomodeset を追加する。
setparams 'Try or Install Ubuntu'
set gfxpayload=keep
linux /casper/vmlinuz --- quiet splash
initrd /casper/initrd
こんな感じ。
linux /casper/vmlinuz --- quiet splash nomodeset
あとは画面表示に従い F10 とかで通常起動を行うと、フリーズすることなくインストールできる。
インストール後の恒久対応
インストールが無事に終わっても普通に起動するとフリーズするので、同様の設定を恒久的に入れておく必要がある。Ubuntuをリカバリモードで起動し、GRUBの設定ファイルに nomodeset を追加しておけばよい。
下記手順で設定する。
① 電源ボタンを押して起動後、ThinkPadロゴ表示中に ThinkVantage ボタンを押す。これで起動メニューが表示される。
② F12 to choose temporary startup device の表示に従い、F12 キーを押す
③ Ubuntuがインストールされているディスクを選択して Enter キーを押し、その直後から ESC キーを連打
④ GRUBメニューが表示されるので、Advanced options for Ubuntu を選択
⑤ リカバリモード(Ubuntu, with Linux 6.8.0-48-generic (recovery mode) みたいなやつ)を選択
⑥ リカバリメニューで root Drop to root shell prompt を選択
⑦ root ユーザでシェルに入れるので、下記手順で設定追加
/etc/default/grub の GRUB_CMDLINE_LINUX に nomodeset を追加
$ vi /etc/default/grub
# /boot/grub/grub.cfg.
# For full documentation of the options in this file, see:
# info -f grub -n 'Simple configuration'
GRUB_DEFAULT=0
GRUB_TIMEOUT_STYLE=hiddenGRUB_CMDLINE_LINUX="nomodeset"
GRUB_TIMEOUT=0
GRUB_DISTRIBUTOR=`( . /etc/os-release; echo ${NAME:-Ubuntu} ) 2>/dev/null || echo Ubuntu`
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
GRUB_CMDLINE_LINUX="nomodeset" # これ
...
$ update-grub
⑧ リカバリメニューに戻って resume Resume normal boot から通常起動を行う
まとめ
1日ほど使っている限りでは問題なく動作しているので、これで問題なさそう。
リカバリモードでの起動で地味に手間取ったけど、実はログイン前だとフリーズしなさそうだったので、ログイン画面で Ctrl+Alt+F2 とかでコンソールログインすればフリーズせずに /etc/default/grub の編集ができたかもしれない(未確認)。
参考
ちょっとしたスクリプトをWindows/Linux/macOS兼用で動作させる
ちょっとそういうのが必要になったので
確か Embulk でこんな感じのことをやっていたはず…という記憶を頼りに作ってみた。 とりあえず動くけど、後述のとおり行儀のいい方法ではない&制約事項もあるので、使う場合は要注意。
環境
条件
- スクリプト内ではNode.jsで複数行のソースコードを実行したい。Node.jsはインストール済みでパスが通っている前提。
- 実行は1ファイルで完結させたい。実行時引数とかも無し。
- Windows(バッチファイル)でもLinux/macOS(bash/zsh)でも全く同じファイルを使う。
できあがったもの
こんな感じ。
: <<BAT @echo off echo ^ console.log('Node.js on Windows'); ^ let a = 1; ^ let b = 2; ^ console.log("a + b = " + (a + b)); | node.exe exit /b BAT node <<-EOS console.log('Node.js on Linux/macOS') let a = 1 let b = 2 console.log("a + b = " + (a + b)) EOS
runanywhere.bat 的な名前で保存し、各環境で実行する。
改行コードは LF にする。
実行例
Windows(コマンドプロンプト)
C:\work> runanywhere.bat Node.js on Windows a + b = 3
Linux(bash), macOS(zsh)
$ ./runanywhere.bat Node.js on Linux/macOS a + b = 3
仕組み
スクリプトの大枠は下記のとおり。
: <<BAT バッチファイル(Windows)として動作するコード exit /b BAT シェルスクリプト(Linux/macOS)として動作するコード
<<BAT ~ BAT にバッチファイルのコードを書いてあり、その後ろにシェルスクリプトのコードが続くという構成になっている。
シェルスクリプト(Linux/macOS)から見ると <<BAT ~ BAT の部分はコードはヒアドキュメントとして扱われ、: という何もしないコマンドに渡される。つまり、ただの文字列を何もしないコマンドに渡しているだけなので何も起こらず、その次に続くシェルスクリプトのコードが普通に実行される。
バッチファイル(Windows)から見ると : は GOTO コマンドのラベルであり、それだけでは特に何も処理は行われない。また、 : <<BAT のような表記も構文上は問題が無い。
このため、その次に続くバッチファイルのコードが普通に実行されて、最後に exit /b で終了する。それ以降のコードは実行されないので、後ろにシェルスクリプトのコードがあっても問題は無い。
あとは各環境でNode.jsにソースコードを渡して実行する処理を書けばOK。
シェルスクリプトの場合は普通にヒアドキュメントが書けるので、それをそのままNode.jsに流し込む。
バッチファイルの場合はヒアドキュメントが無いので、1行にまとめて標準入力経由でNode.jsにコードを渡している。
今回は読みやすさを考慮して ^ で改行しているが、実態は下記のようなコードと同じ。
echo console.log('Node.js on Windows'); let a = 1; let b = 2; console.log("a + b = " + (a + b)); | node.exe
制約事項
改行コードは LF にする必要がある。でないとLinux/macOSでエラーになる。バッチファイル的には良くないが、だいたい動くので許容する。
# CR/LFにすると… $ ./runanywhere.bat : not foundre.bat: 12: Node.js on Linux/macOS a + b = 3
ただし、日本語(マルチバイト文字)は使えない。バッチファイルで改行コードが LF の場合、日本語が含まれるとコマンドの一部が削られてしまい、エラーになる。
ちなみにこの挙動は マルチバイト文字を含まない場合にも発生することがあるらしい ので注意。
# こんな感じでコメントに日本語を入れてみると… : <<BAT @echo off rem 日本語 echo ^ ...
# 実行時にコマンドが削られてエラーになる C:\work>runanywhere.bat C:\work>ho off 'ho' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。 C:\work>m 日本語 'm' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。 ...
バッチファイルの部分を CR/LF 、シェルスクリプトの部分を LF にすれば解決するはずだけど、手作業で作るスクリプトでそれを維持し続けるのはさすがに厳しいので、LF に統一というのが落としどころだと思う。
まとめ
とりあえず動くので使えるんだけど、改行コードが LF のバッチファイルってことであまり良くないので、多用は禁物。
xargsで複数のパラメータに対してプレースホルダを使う
環境
- Ubuntu 22.04
xargsで -n と -I が併用できない問題
xargs を使う際、-I オプションを使ってパラメータをプレースホルダに差し込むというのをよくやります。
# テスト用ファイル $ cat data.txt aaaa bbbb cccc dddd # ファイルの各行に対して xargs でコマンド実行 # -I で指定したプレースホルダ @ の場所にパラメータが正しく置換されている $ cat data.txt | xargs -I@ echo "The input is [@]." The input is [aaaa]. The input is [bbbb]. The input is [cccc]. The input is [dddd].
パラメータが1つの場合はこれでいいんですが、-n オプションで2つ以上のパラメータを使おうとすると -I が使えないため、すごく困ります。
# xargs -n2 でパラメータ2つずつに対してコマンド実行 # 先に指定した -I@ が無視されて -n2 だけが有効になり、パラメータの置換が行われない $ cat data.txt | xargs -I@ -n2 echo "The inputs are [@]." xargs: warning: options --replace and --max-args/-n are mutually exclusive, ignoring previous --replace value The inputs are [@]. aaaa bbbb The inputs are [@]. cccc dddd
sh -c 経由で実行して回避する
これは xargs に渡すコマンドを sh -c 経由で実行し、シェルの引数 $1, $2, ... を使うことで代替できます。
$ cat data.txt | xargs -n2 sh -c 'echo "The inputs are [$1, $2]."' sh The inputs are [aaaa, bbbb]. The inputs are [cccc, dddd].
xargs から sh -c 'echo "The inputs are [$1, $2]."' sh aaaa bbbb のような形で sh にパラメータが渡されるので、あとは sh で実行するコマンドの中で $1, $2 等を好きなように使えばOK、という具合です。
コマンド末尾の sh は、 $0 として渡されるコマンド名を明示的に指定しているだけです。
今回の場合であればこれを無くして xargs -n2 sh -c 'echo "The inputs are [$0, $1]."' のようにしてもよいのですが、例えばコマンド内で $@ を使った場合に $0 は除外されるといった扱いの違いもあるので、指定しておくとちょっとだけ安心です。
参考
SQLで is null or 〜 を一発でやる is distinct from の話
環境
- PostgreSQL 15
- 本記事の機能はPostgreSQLで試していますが、
is distinct fromはANSI標準なので、他のDBMSでもサポートされていれば使えます
- 本記事の機能はPostgreSQLで試していますが、
SQLで null を含むカラムへの条件指定
ご存知のとおり、SQLでの値の比較の際に = とか <> とかで null と比較すると、結果は常に null になります。
このため、null を含むカラムに対して「ある値に一致しない行を、null も含めて出したい」みたいなことをやる場合は is null の条件も加えて比較する必要があります。
例: テーブル nantoka_data
-- 元データ select * from nantoka_data;
| id | name | num |
|---|---|---|
| 1 | 'foo' | 100 |
| 2 | 'bar' | 200 |
| 3 | null | null |
-- num が null の行は num <> 100 だと抽出されない select * from nantoka_data where num <> 100;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
-- is null の条件を加えて、カラム num の値が 100 と一致しない行を全て抽出する select * from nantoka_data where num is null or num <> 100;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
| 3 | null | null |
is distinct from を使ってみる
で、これを一発で行う is distinct from というものがあります。
入力のどちらかがnullの場合、通常の比較演算子は真や偽ではなく(「不明」を意味する)nullを生成します。 例えば7 = nullはnullになります。7 <> nullも同様です。 この動作が適切でない場合は、IS [ NOT ] DISTINCT FROM述語を使用してください。
a IS DISTINCT FROM b a IS NOT DISTINCT FROM b
これを使って前述のSQLを書き換えると、こんな感じ。
-- select * from nantoka_data where num is null or num <> 100; と同じ select * from nantoka_data where num is distinct from 100;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
| 3 | null | null |
ちなみに構文は expression IS DISTINCT FROM expression なので、値だけでなく式が書けます。
このため、値の一致のみでなく、大小比較や like での部分一致なんかもできます。
-- num < 150 に該当しない行を、nullも含めて抽出 select * from nantoka_data where num < 150 is distinct from true;
| id | name | num |
|---|---|---|
| 2 | 'bar' | 200 |
| 3 | null | null |
-- name like 'b%' に該当しない行を、nullも含めて抽出 select * from nantoka_data where name like 'b%' is distinct from true;
| id | name | num |
|---|---|---|
| 1 | 'foo' | 100 |
| 3 | null | null |
正直ちょっと冗長なので is null or 〜 と書いてもあまり変わらない気がするのと、「どこにも not って書いてないのに否定条件」というところに若干のわかりづらさはありますが、覚えておくとどこかで使えるかもしれません。
参考
複合インデックスを使うにはwhere句に書くカラムの順番を合わせないとダメとか無いですよねという話
概要
「複合インデックスを使うにはwhere句に書くカラムの順番をインデックスの定義順と合わせなければならんのじゃよ *1」って言われて、いやそんなまさか…?と思ったので念のため検証してみたメモ。
結論から言うと、試した限りではそんなことはなかった。
どういうことかというと
こういうテーブルとインデックスがあったときに…
create table sample_data ( id integer primary key, colum_a integer not null, colum_b integer not null, colum_c integer not null ); create index idx_sample_data_01 on sample_data (colum_a, colum_b, colum_c);
こう書くと複合インデックス idx_sample_data_01 が使われるけど
-- where句のカラムの順番を複合インデックスでの定義順 colum_a, colum_b, colum_c に合わせる select * from sample_data where colum_a = 100 and colum_b = 100 and colum_c = 100;
こう書くと使われない、という主張らしい。
-- where句のカラムの順番を複合インデックスでの定義順とは異なる順番にする select * from sample_data where colum_c = 100 and colum_b = 100 and colum_a = 100;
というわけで試してみる
環境
- PostgreSQL 15.3
- MySQL 8.0.33
いずれもDocker Hubの公式イメージを使う。
手順
1. Dockerコンテナ立ち上げ
$ docker run -d \ --name postgres \ -p 127.0.0.1:5432:5432 \ -e POSTGRES_PASSWORD=postgres \ -v pgdata:/var/lib/postgresql/data \ postgres:15.3 $ docker run -d \ --name mysql \ -p 127.0.0.1:3306:3306 \ -e MYSQL_ROOT_PASSWORD=mysql \ mysql:8.0.33
2. テーブルを作ってデータを投入
前述のテーブルにデータを50,000件入れて試してみる。
こんな感じのSQLファイルを作っておいて
-- insert.sql create table sample_data ( id integer primary key, colum_a integer not null, colum_b integer not null, colum_c integer not null ); create index idx_sample_data_01 on sample_data (colum_a, colum_b, colum_c); insert into sample_data values (1, 1, 1, 1), (2, 2, 2, 2), (3, 3, 3, 3), -- 中略 (49999, 49999, 49999, 49999), (50000, 50000, 50000, 50000);
各DBに投入する。analyze もやっておく。
# PostgreSQL $ psql -h localhost -U postgres -f insert.sql $ psql -h localhost -U postgres -c 'analyze sample_data;' # MySQL $ mysql -p -u root mysql < insert.sql $ mysql -p -u root mysql -e 'analyze table sample_data;'
ちなみにデータはこんな感じのRubyコードで作ったもの。
values = 1.upto(50000).map {|n| "(%d, %d, %d, %d)" % [n, n, n, n] }.join(",\n") puts "insert into sample_data values #{values};"
4. 試してみる
各条件で実行計画を取得してみて、インデックスが使われるかどうかを確認する。
PostgreSQL
まずはwhere句のカラムの順番を複合インデックスでの定義順に合わせた状態でやってみる。 これは当然インデックスが使われる。
explain verbose select * from sample_data where colum_a = 100 and colum_b = 100 and colum_c = 100;
QUERY PLAN | -----------------------------------------------------------------------------------------------------------+ Index Scan using idx_sample_data_01 on public.sample_data (cost=0.29..8.31 rows=1 width=16) | Output: id, colum_a, colum_b, colum_c | Index Cond: ((sample_data.colum_a = 100) AND (sample_data.colum_b = 100) AND (sample_data.colum_c = 100))|
QUERY PLAN が Index Scan using idx_sample_data_01 〜 となっているので、ちゃんと複合インデックスが使われていることがわかる。
次にwhere句のカラムの順番を複合インデックスでの定義順とは逆にしてみる。
explain verbose select * from sample_data where colum_c = 100 and colum_b = 100 and colum_a = 100;
QUERY PLAN | -----------------------------------------------------------------------------------------------------------+ Index Scan using idx_sample_data_01 on public.sample_data (cost=0.29..8.31 rows=1 width=16) | Output: id, colum_a, colum_b, colum_c | Index Cond: ((sample_data.colum_a = 100) AND (sample_data.colum_b = 100) AND (sample_data.colum_c = 100))|
…普通にインデックス使われている様子。コストも全く一緒。
さらに順番を入れ替えてみたけど、やっぱり結果は同じ。
explain verbose select * from sample_data where colum_c = 100 and colum_a = 100 and colum_b = 100;
QUERY PLAN | -----------------------------------------------------------------------------------------------------------+ Index Scan using idx_sample_data_01 on public.sample_data (cost=0.29..8.31 rows=1 width=16) | Output: id, colum_a, colum_b, colum_c | Index Cond: ((sample_data.colum_a = 100) AND (sample_data.colum_b = 100) AND (sample_data.colum_c = 100))|
MySQL
where句のカラムの順番を複合インデックスでの定義順に合わせた場合。 当然インデックスが使われる。
explain select * from sample_data where colum_a = 100 and colum_b = 100 and colum_c = 100;
Name |Value | -------------+------------------+ id |1 | select_type |SIMPLE | table |sample_data | partitions | | type |ref | possible_keys|idx_sample_data_01| key |idx_sample_data_01| key_len |12 | ref |const,const,const | rows |1 | filtered |100.0 | Extra |Using index |
type = ref、key = idx_sample_data_01 なので、ちゃんと複合インデックスが使われている。
PostgreSQLと同様、順番を逆にしたり入れ替えたりしてもやっぱり結果は変わらず。
explain select * from sample_data where colum_c = 100 and colum_b = 100 and colum_a = 100;
Name |Value | -------------+------------------+ id |1 | select_type |SIMPLE | table |sample_data | partitions | | type |ref | possible_keys|idx_sample_data_01| key |idx_sample_data_01| key_len |12 | ref |const,const,const | rows |1 | filtered |100.0 | Extra |Using index |
explain select * from sample_data where colum_c = 100 and colum_a = 100 and colum_b = 100;
Name |Value | -------------+------------------+ id |1 | select_type |SIMPLE | table |sample_data | partitions | | type |ref | possible_keys|idx_sample_data_01| key |idx_sample_data_01| key_len |12 | ref |const,const,const | rows |1 | filtered |100.0 | Extra |Using index |
こんな話はどこから出てきた?
試した結果を見てそりゃそうだよなと思いつつもうちょっと調べてみると、「達人に学ぶSQL徹底指南書」の初版第4刷 p.205 にはこんなことが書いてあった。
(col_1, col_2, col_3) に対してこの順番で複合インデックスが張られているとします。 その場合、条件指定の順番が重要です。
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500; ○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100; × SELECT * FROM SomeTable WHERE col_1 = 10 AND col_3 = 500; × SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500; × SELECT * FROM SomeTable WHERE col_2 = 100 AND col_1 = 10;
必ず最初の列(col_1)を先頭に書かねばなりませんし、順番も崩してはいけません。
最後の例は条件を col_2, col_1 の順番で書いていて × となっているので、今回の話と合致する。
しかし同書籍の第2版では下記のように変わっており、WHERE col_2 = 100 AND col_1 = 10 の例が無くなっている。
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500; ○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100; × SELECT * FROM SomeTable WHERE col_1 = 10 AND col_3 = 500; × SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500;
初版の正誤表 にも当該部分の記載が無いので、もしかしたら昔はそういう制約事項があったのかもしれない。
まとめ
少なくとも PostgreSQL 15.3 と MySQL 8.0.33 では、where句のカラムの順番を複合インデックスの定義順と合わせなくても大丈夫そう。
いにしえのDBは知らん。
参考
各DBの実行計画の読み方の参考。
IntelliJ IDEAでSpring Bootの@Valueアノテーションの引数にプロパティ値が展開されないようにする
環境
概要
いつの頃からか、IntelliJ IDEAでSpring Bootの @Value アノテーションの引数部分に実際のプロパティ値が展開されるようになりました。
こう書くと…
# application.yaml demo: someString: nanraka no mojiretsu
public class DemoController { @Value("${demo.someString}") String someString; }
↓こうなる
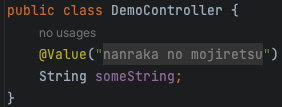
すごくウザいので、OFFにします。
こうする
メニューから
IntelliJ IDEA > Preferences... > Editor > General > Code Foldingと設定画面を開き *1 、Java の I18n strings のチェックを外します。

あとはOKボタンでダイアログを閉じてIntelliJ IDEAを終了し、再度起動すればOK。
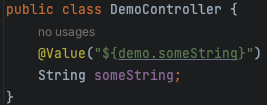
ソースコードに書かれたとおりのキーが表示されるようになりました。